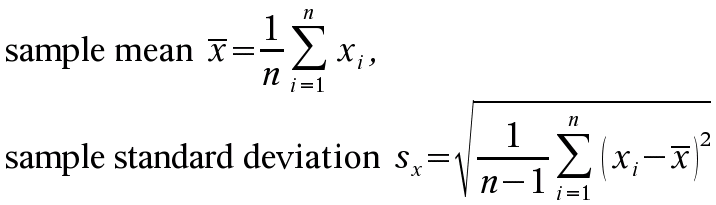
Use the applet below to practise constructing confidence intervals using a simple scientific calculator and a table of the Student t distribution. You can use the calculator and table of the Student t distribution provided, though it’s a good idea to find out how your own calculator works.
To construct a confidence interval you need to
There are formulas (see below) for the sample statistics, but it is sensible to learn how to use a calculator to find these.
The reason for constructing a confidence interval is so that you use a sample (small subset) to say with confidence something about a large population. For example, you might want to measure average height or weight or speed or price. The population is too big to measure everything; so you measure a sample and use that to estimate what you would get if you could measure the population.
You can't measure a population property exactly from a sample but you can be very confident about how well you have estimated it provided you follow the following simple rules about choosing the sample.
The sample also has to have at least two observations, though the bigger the sample is, the smaller (and hence more accurate) the confidence interval will be.
You should choose your confidence level at this stage. A confidence level of 100% will always be infinitely wide. So we have to choose something smaller. On the other hand, you’re unlikely to want a confidence level less than 50%. The most commonly used value is 95% though values of 90% and 99% are also common.
We will estimate a confidence interval for the population mean μx. To do this we need some sample statistics and we will find them using a calculator. If you want to know the formulas, see below.
We need three sample statistics:
For small samples, it is often easiest to use a calculator to find the mean, standard deviation and standard error. For larger samples, you might want to use a spreadsheet program such as openoffice or a statistical computing package. If you use a calculator, work to three significant figures (or three decimal places). There’s little point to being more accurate because the values in the Student t table are only given to this accuracy.
Any modern scientific calculator should can find the sample statistics for you and you don’t need an expensive one—the ones you see in the supermarket for a few euros are fine. Usually you have to set the calculator to use a special statistics or standard deviation mode and the typical calculator notation is a bit strange, but commonly they come with an instruction card in the case that should help.
You may need to start by setting the mode of the calculator. For example, my
Casio fx-83WA can be set to SD (standard deviation) mode using
2
The mode is shown by a little SD in the display. Fortunately most
calculators remember that they are in statistics mode even when they
are switched off. So I just keep my calculator in this mode permanently. They
also usually remember any statistics they have collected even when switched
off. This is a particularly convenient feature because it means you only have
to type in data once. But it also means that you have to clear the statistics
memory before working with a new set of data. Typically, you clear statistics
memory with something like
or
Once you’ve cleared statistics memory, you need to enter data. This is
straigghtforward and typically uses a
or
buuton. For example, to enter five values
147.57, 130.31, 119.07, 116.87 and 113.05 simply type
147.57
130.31
119.07
116.87
113.05
and the data is entered.
Now you can find the sample statistics without reëntering the data:
Some calculators will tell you the sample size if you’ve forgotten it (look for a shifted button). The one button you should avoid is the button: it calculates the population standard deviation for your data and is not helpful for estimating confidence intervals of small samples.
Looking up the table of the Student t distribution should be easy. You decide what tail area to look for and the degrees of freedom and choose the corresponding value in the table.
You get the tail area from the confidence level. If the confidence level is 100(1 − α)% then the tail area is α/2. For example, if you want a 95% confidence interval, take the remaining 5% and divide by 2 to get a tail area of 2.5% or 0.025.
Why do we use α/2 and not α? We want a confidence interval corresponding to the middle 100(1 − α)% of the Student t distribution. So we exclude an area α/2 from under either end of the distribution curve. The t distribution is symmetric, so we don’t need two t values and just use one value, corresponding to α/2. We use this value twice when constructing the confidence interval and so exclude the right amount of the distribution.
The degrees of freedom is usually easier. It is just n − 1, where n is the sample size.
The degrees of freedom is usually written ν and the value (1 less than the sample size) reflects the idea that you can’t have a t distribution for a sample size of 1. There is nothing to prevent someone from creating a table with sample size instead of degrees of freedom, but I will assum you want to know how to work with the kind of table that people actually make.
The tricky part with degrees of freedom is deciding what to do if you can’t find the degrees of freedom you’re looking for in the table. When this happens there are two things you can do. You can use the nearest value. For example, if you have degrees of freedom 32, you could use the t value corresponding to 30. Or you could use the last (∞) row of the table. You should certainly do this for values over 120 and can reasonably do this for any value that doesn$rsquo;t have its own row in the table. You should notice that as the degrees of freedom gets bigger and bigger, it gets closer and closer to the last row of the table.
When degrees of freedom is ∞ the distribution is a standard Gaussian or normal) distribution rather than a t distribution, but the table still works. In fact, it’s easier to look up the table of the Student t distrribution than it is to find the same values in the normal distribution table. So if you have both tables, the Student t table is the one to look at first.
Writing down the confidence interval should now be easy. It is just the sample mean plus or minus t standard errors:
x ± tα/2, n − 1 × STEM
You can use the calculator to find this. It is commonly expressed as
x − tα/2, n − 1 × STEM < μ < x + tα/2, n − 1 × STEM
where, of course, you replace the limits by actual figures.
Please report all bugs to me at the address below. Suggestions for improvements are also welcome.
If you find the calculator button doesn’t display properly, try installing a more recent version of java. Java 2, 1.5 looks a lot better than 1.4 and supports generics, which is a good reason to install it anyway. I also can’t find a way to display the mean of x in simple HTML, so suggestions are welcome. I don’t want to use an image because the fonts on this page should be rescalable.
You will need a java plugin for this web page to work properly. If you don't have one, you can get one from Sun Microsystems. Some java plugins, notably the ones from Microsoft, but also some older plugins won't work with the java applet on this page.
You may freely download and use the source code for the applet. It is written in Java.